BorgNetzWerk Proposal 2026: Difference between revisions
| Line 411: | Line 411: | ||
=== Meilenstein 2: Treibholz === | === Meilenstein 2: Treibholz === | ||
[[File:On FAIR.png|thumb|right]] | |||
Ziel: Prototyp durch erste Nutzer:innen testen, Feedback sammeln und Kommunikations-/Outreach-Maßnahmen fahren, um Ehrenamtliche und Pilotpartner zu gewinnen. | Ziel: Prototyp durch erste Nutzer:innen testen, Feedback sammeln und Kommunikations-/Outreach-Maßnahmen fahren, um Ehrenamtliche und Pilotpartner zu gewinnen. | ||
| Line 424: | Line 425: | ||
==== Printmaterial: 1.000 € ==== | ==== Printmaterial: 1.000 € ==== | ||
Flyer und Handouts für Veranstaltungen und Outreach; gezielt zur Gewinnung von Ehrenamtlichen, Förderern und Kooperationspartnern. | Flyer und Handouts für Veranstaltungen und Outreach; gezielt zur Gewinnung von Ehrenamtlichen, Förderern und Kooperationspartnern. | ||
=== Meilenstein 3: Floß === | === Meilenstein 3: Floß === | ||
Revision as of 22:31, 25 October 2025

Zusammenfassung
Hintergrund: Wissenschaftskommunikation ist ein fragmentiertes Feld, von ihren Artefakten wie Videos und Podcasts, über ihre Personen wie Wissenschaftler*innen und Content Creators, bis hin zu den Organisationen wie Universitäten und Unternehmen. Es existiert kein Überblick, nicht einmal innerhalb Deutschlands, nicht einmal innerhalb eines Forschungsfeldes, wer wie wann wo worüber kommuniziert. Viele verstreute Individuen und kleine Netzwerke versuchen, gute Wissenschaftskommunikation zu betreiben und Lücken in der Wissenschaftskommunikation zu finden, zu verstehen und zu füllen. Zur Übersicht fehlt es an Wissensinfrastruktur, einem "robusten Netzwerk von Menschen, Artefakten und Institutionen, das spezifisches Wissen generiert, teilt und pflegt" - wie ein Wikipedia für die Wissenschaftskommunikation.
Ziel: Aufbau einer kollaborativen Infrastruktur zur Förderung der FAIR-Datenprinzipien (Findability, Accessibility, Interoperability, Reusability) für die Kuratierung, Annotation und den Zugang zu wissenschaftlichen Videos und Podcasts.
Ansatz: Und wie Wikimedia hinter Wikipedia steht, hat BorgNetzWerk - Gesellschaft zur Vernetzung Freien Wissens e.V. es sich zur Aufgabe gemacht, die Wissensinfrastruktur zu fördern. Wir schaffen eine Übersicht, mit den Erkenntnissen und Technologien der offenen Datenwissenschaft und digitalen Bibliotheken, von MediaWiki und Wikibase bis hin zu ORKG und AV-Portal. Wir vernetzen Individuen und Organisationen, miteinander und mit der Gesellschaft, sodass Suchen nach verständlichem Wissen an verlässlichere Quellen führen. Wir begegnen der Desinformationsflut mit drei Dingen:
- Der Gewissheit, dass immens wertvolle Infrastrukturen bereits jetzt existieren und gestärkt werden müssen,
- Der Sicherheit, dass, wenn wir nichts unternehmen, gesellschaftliche Kipppunkte durch Verunsicherung und Missverständnisse sehr bald erreicht sein könnten,
- wir diesen Weg nicht allein, sondern nur gemeinsam bestreiten können.
Darum haben wir den Verein gegründet, darum bauen wir ihn und insbesondere das WissKomm Wiki, das Wiki für wissenschaftliche Videos und Podcasts, seit 2021 stetig weiter aus. Mit diesem Proposal wollen wir das Feedback der Vorjahre, von startsocial Reviewern über Forschungsanträge bis hin zu akademischen Peer Reviews, in einem Antrag Bündeln: Das BorgNetzWerk Proposal 2026, mit dem Ziel, noch im Jahr 2026 die Gesellschaft mit Werkzeugen wie dem WissKomm Wiki zu befähigen, zu einer gemeinsamen Wirklichkeit zusammenzufinden.
Unterstützer*innen
(Details unter BorgNetzWerk Proposal 2026#Unterstützer)
- "Wir sehen das WissKomm‑Wiki als Teil unserer Mission, der Gesellschaft Informationen bereitzustellen. Es ergänzt die bestehenden Systeme, den Open Research Knowledge Graph für wissenschaftliche Artikel und das TIB AV-Portal für Videos, indem es Informationen zu wissenschaftlichen Videos und Podcasts aufbereitet und strukturiert verfügbar macht. Die TIB unterstützt dieses Ziel: Das WissKomm‑Wiki ist eine sinnvolle Ergänzung unserer technischen Infrastruktur, die wir langfristig fördern werden."
- Prof. Dr. Claudia Frick, Professorin für Informationsdienstleistungen und Wissenschaftskommunikation an der Technischen Hochschule Köln und Wissenschaftskommunikatorin beim Podcast „Das Klima“
- "Ich sehe im "WissKomm Wiki" eine Chance, insbesondere die inhaltliche Beforschung von Wissenschaftskommunikations-Podcasts voranzubringen, die aufgrund lückenhafter Transkriptionen bislang ihr volles Potenzial noch nicht entfalten konnte. Das "WissKomm Wiki" fördert damit nicht nur eine offenere Wissenschaft und eine transparentere Wissenschaftskommunikation, sondern senkt zugleich Barrieren für Forschung und Praxis. Durch den offenen Zugang zu Daten, Transkripten und Analysen werden die Prinzipien von Open Science gestärkt und neue Möglichkeiten für kollaborative Forschung geschaffen. Das Projekt spiegelt somit meine eigenen Ziele in der Wissenschaftskommunikation und in der Wissenschaftskommunikationsforschung wider."
- Prof. Dr. Peter Adamson, Professor für spätantike und arabische Philosophie LMU München und Host des "History of Philosophy" Podcasts
- "Tim, der Gründer des Netzwerks, konnte mithilfe automatischer Spracherkennung Transkripte für Audio-Interviews erstellen, die ich in den letzten zehn Jahren und darüber hinaus geführt habe, was zu einer unschätzbar wertvollen Ressource für die Nutzer meiner Podcast-Website geführt hat. Als jemand, der sich sehr für frei zugängliche Öffentlichkeitsarbeit engagiert, denke ich, dass dies nur ein kleiner Vorgeschmack auf das ist, was potenziell möglich ist. Je mehr wir Informationen und deren Analyse allgemein zugänglich machen, desto weniger Hindernisse gibt es in den Bereichen Bildung, Kommunikation usw., was nur eine Gute Sache sein kann![1]"
- Simone Herpich, Referentin für Wissenschaftskommunikation am KIT und Mitarbeiterin im Team des YouTube Kanals Akkudoktor
- Gerrit Hansen
Struktur
Ausgangslage

Dieser Abschnitt beschreibt den aktuellen Stand von BorgNetzWerk und des WissKomm‑Wiki. Zunächst werden die Grundlagen kurz definiert, dann die technischen, organisatorischen und wissenschaftlichen Bausteine beleuchtet, die bereits vorhanden sind.
Grundlagen
Im Kern adressiert das Projekt die (i) Auffindbarkeit, (ii) Nachnutzbarkeit und (iii) Verlässlichkeit wissenschaftsrelevanter audio‑visueller (AV) Medien. Wir betrachten Videos, Podcasts sowie damit verbundene Metadaten und Inhalte, die durch strukturierte Indizierung, Transkription und Annotation für Wissenschaft und Praxis nutzbar gemacht werden können. Die Arbeit orientiert sich an FAIR‑Prinzipien (Findable, Accessible, Interoperable, Reusable) und an offenen, föderierten Architekturen (Wikibase, ORKG, AV‑Portal), berücksichtigt aber explizit nationale Rechtsrahmen (Urheber‑ und Persönlichkeitsrechte) in Deutschland.
- Creative Commons wo möglich:
- Ziel ist es, Inhalte möglichst offen zu veröffentlichen, soweit Lizenzlage und Rechteinhaber*innen das erlauben. Viele Metadaten, annotierte Beschreibungen und strukturierte Bewertungen sollen unter offenen Lizenzen stehen. Transkripte und volle Textversionen können je nach Einwilligung und Rechtslage weiterhin urheberrechtlich eingeschränkt sein. Diese differenzierte Lizenzstrategie unterscheidet das WissKomm‑Wiki von rein gemeinfreien Projekten wie Wikisource und ist Teil unseres Risikmanagements.
- Wissenschaftlich relevante Videos und Podcasts
- Unsere Einordnung von "relevant" umfasst nicht streng akademische Publikationen, sondern audiovisuelle Wissen{schaft}svermittlung, die in öffentlichen Debatten Wirkung entfalten (z. B. Erklärvideos, Wissenschaftspodcasts, etablierte TV‑Formate). Das Projekt erfasst daher Materialien, die für Forschung und Gesellschaft relevant sind, auch und insbesondere wenn sie nicht in bestehende Kataloge wie Wikidata fallen.
- Transparenz wo möglich
- Transparenz ist unser Leitprinzip: soweit rechtlich möglich veröffentlichen wir Herkunftsangaben, Bewertungsmethoden, Konfliktinteressen und Workflow‑Beschreibungen (z. B. Einwilligungsstatus von Creators). Wir arbeiten mit transparenten Regeln, die Nutzer*innen nachvollziehbare Entscheidungen und den Umgang mit sensiblen Inhalten näher bringen.
Bestehende Infrastruktur
Das Projekt fügt sich in eine bestehende, heterogene Landschaft von Open‑Science‑Infrastruktur ein. Im Folgenden listen wir die wichtigsten Plattformen, Dienste und Projekte auf, die in vorigen Anträgen und Gutachten genannt wurden, und geben einen kurzen Vergleich ihrer Zwecke, Stärken und Grenzen.
| Name | Content | Web-Service | Linked-Data | Data Export | API | freier Zugang | Volltext | Open-Source | Community-Edits | kommerziell | vernetzbar |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Wikipedia | Text, Bilder zu relevantem | ✔ | ✘ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✘ | ✔ |
| Wikidata | strukturierte Entitäten von relevantem | ✔ | ✔ | ✔ | ✔ | ✔ | ✘ | ✔ | ✔ | ✘ | ✔ |
| Wikisource | Volltexte gemeinfreier Textwerke | ✔ | ✘ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✘ | ✔ |
| TIB AV-Portal | Dateien und Metadatan zu Video | ✔ | ✘ | ✔ | (✔) | ✔ | ✔ | ✘ | ✘ | ✘ | ✔ |
| Open Educational Resources Search Index (OERSI) | Metadatan zu OER | ✔ | (✔) | ✘ | ✘ | ✔ | ✔ | ✘ | ✘ | ✘ | ✔ |
| Zenodo | Dateien und Metadaten aller Art | ✔ | ✘ | ✔ | ✔ | ✔ | ✔ | ✘ | ✘ | ✘ | ✔ |
| Zotero | Metadaten zu Referenzen | ✔ | ✘ | ✔ | ✔ | ✔ | ✔ | ✘ | ✔ | ✘ | ✔ |
| arXiv | Preprints zu wissenschaftlichen Artikeln | ✔ | ✘ | ✔ | ✔ | ✔ | ✔ | ✘ | ✘ | ✘ | ✔ |
| ORCID | Metadaten zu Personen | ✔ | ✘ | ✔ | ✔ | ✔ | ✔ | ✘ | ✘ | ✘ | ✔ |
| Internet Archive | Speicherung von Websiten | ✔ | ✘ | ✔ | ✔ | ✔ | ✔ | ✔ | ✘ | ✘ | ✔ |
| Open Research Knowledge Graph (ORKG) | strukturierte Paper‑Daten | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✘ | ✔ | ✘ | ✔ |
| World Lecture Project | Videos; Metadaten | ✔ | ✘ | ✘ | ✘ | ✔ | ✘ | ✘ | ✘ | ✘ | ✔ |
| Wissen{schaft}spodcasts (Wisspod) | Audio Metadaten | ✔ | ✘ | ✘ | ✘ | ✔ | ✘ | ✘ | ✘ | ✘ | ✔ |
| Weitere Content‑Portale (YouTube; Podigee; Spotify; ...) | Dateien und Metadatan zu Audio-/Video | ✔ | ✘ | (✔) | (✔) | ✔ | (✔) | ✘ | ✘ | ✔ | ✔ |
| IMDB / fernsehserien.de | Metadaten zu Serien | ✔ | ✘ | ✘ | ✘ | ✔ | ✘ | ✘ | ✔ | ✔ | ✔ |
| ARD Mediathek / ZDF Mediathek | Video-Daten und Metadaten zu ÖRR-Sendungen; | ✔ | ✘ | ✘ | ✘ | ✔ | ✘ | ✘ | ✘ | ✘ | ✔ |
| ZDF Medien‑Archiv | Video-Dateien und Metadaten zu ZDF-Sendungen | ✘ | ✘ | ✘ | ✘ | (✔) | ✘ | ✘ | ✘ | ✘ | (✔) |
| Science Media Center Germany | Hintergrundtexte; Presseinfos | ✔ | ✘ | ✘ | ✘ | ✘ | ✘ | ✘ | ✘ | ✘ | ✔ |
| WissKomm Wiki (geplant) | Metadaten, Transkripte und Annotationen zu Videos & Podcasts | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✘ | ✔ |
Im Vergleich ist unser Projekt Wikidata und Wikisource am ähnlichsten. Wären die folgenden zwei Probleme nicht, könnten wir vermutlich das WissKomm Wiki mithilfe dieser beiden Projekte umsetzen, jedoch:
- Beide, insbesondere Wikisource[2], sind auf gemeinfreie (Public Domain) Inhalte beschränkt,
- Beide, insbesondere Wikidata[3], sind technisch nicht in der Lage, ihren Scope (alle gesamtgesellschaftliche relevanten Inhalte) UND unseren Scope (alle wissenschaftlich relevanten Videos und Podcasts) abzubilden.
Darum existiert das Wikibase Ecosystem und darum untersützt auch Wikimedia Deutschland die Erstellung von spezialisierten, vernetzten Systemen - wie unserem WissKomm Wiki.
Eigene Vorarbeiten
Dieses Unterkapitel fasst die bisherigen wissenschaftlichen Arbeiten zusammen, die den WissKomm‑Wiki‑Ansatz fundieren, und beschreibt den aktuellen Stand der Software‑Prototypen und technischen Infrastruktur.
Überblick über wissenschaftliche Arbeiten
Der aktuellste Preprint fasst unsere konzeptionellen und technischen Beiträge zusammen:
- Wittenborg et al. (2025)[4] SciCom Wiki (Preprint): Beschreibt das SciCom Wiki als offene, FAIR‑orientierte Digitalbibliothek für wissenschaftliche Videos und Podcasts. Kernbeiträge sind (i) eine Anforderungsanalyse mit 53 Stakeholdern und 11 Interviews, (ii) ein prototypischer, Wikibase‑zentrierter Service‑Stack und (iii) eine neurosymbolische, automatisch unterstützte Fact‑Checking‑Pipeline, die audiovisuelle Inhalte in Knowledge‑Graph‑Repräsentationen überführt. Die Arbeit enthält Evaluationsergebnisse aus Nutzerstudien und Expert:innen‑Interviews und begründet, warum eine vernetzte, kollaborative Infrastruktur nötig ist.
Diese Arbeit schließt an eine Vielzahl von Vorarbeiten und verbundenen Entwicklungen im Kontext TIB/BorgNetzWerk an:
- Rohde (2023)[5] Empirische Nutzerstudie: Eine Masterarbeit, die auf einer Umfrage unter 153 Teilnehmenden basiert und die Eignung von ORKG‑basierten Review‑Artefakten für die Wissenschaftskommunikation untersucht. Die Arbeit liefert konkrete Anforderungen an Nutzeroberflächen für Wissensgraphen, Lesedauer‑Metriken sowie Prioritäten für Metadaten‑Felder und Moderations‑Workflows.
- Wittenborg et al. (2024)[6] SWARM‑SLR: Ein Workflow‑ und Toolset zur Automatisierung machine‑actionable Systematic Literature Reviews. SWARM‑SLR fasst 65 Anforderungen entlang des SLR‑Lebenszyklus zusammen, vergleicht vorhandene Tools und stellt einen prototypischen Support‑Workflow bereit, der Crowdsourcing‑ und Automatisierungsmechanismen verbindet, um Effizienz und Reproduzierbarkeit zu erhöhen.
- John (2024)[7] SciKGDash: Masterarbeit zur Entwicklung eines modularen Dashboards zur Kuratierung von Forschungswissensgraphen (SciKGDash). Das Dashboard demonstriert praktikable Metriken und UI‑Patterns zur Unterstützung von Curator:innen‑Teams (z. B. im ORKG) und liefert Evaluationsergebnisse, die unsere Konzepte für Freiwilligen‑Workflows und Qualitätsmetriken unmittelbar stützen.
- Navarrete et al. (2023)[8] Systematischer Übersichtsartikel: Katalog von 257 Untersuchungen zu video‑basiertem Lernen, Taxonomien von Video‑Charakteristika und Überblick über Tools/Methoden; liefert die Forschungslandkarte für die Auswahl relevanter Qualitäts‑ und Metadatenfelder.
- Tremel (2024)[9] Wissenstransparenz und Scoring: Untersuchung und Entwurf eines Score‑Ansatzes zur Bewertung wissenschaftlicher Genauigkeit in Online‑Medien; validiert mit Experteninterviews und Nutzertests. Wichtig für das Design automatisierter Qualitätsindikatoren.
- Stehr (2025)[10] Prototyp‑Implementierung und Evaluation: Masterarbeit, die die Umsetzung des WissKomm‑Wiki‑Prototyps beschreibt, inklusive Nutzerstudien (n≈53) und 11 Stakeholder‑Interviews; liefert Evaluationsergebnisse zu Suchfunktion, UX und zur Integrationsarchitektur.
- John et al. (2026)[11] ExtracTable: Beschreibt ein Human‑in‑the‑Loop‑Werkzeug (ExtracTable) zur beschleunigten Transformation unstrukturierter wissenschaftlicher Publikationen in strukturierte Datenschemata für Knowledge‑Graph‑Integration. Wichtig für das Projekt, weil es zeigt, wie LLM‑gestützte Extraktion plus menschliche Validierung schnelle, reproduzierbare Korpuserstellungen ermöglicht und so Kuratierungsaufwand reduziert.
Auch außerhalb gibt es viele relevante Forschung:
- Makro‑ und Meta‑Analysen & Domänenliteratur: Studien zur Rolle von Video/Audio in der Wissenschaftskommunikation und zu Wirkungen und Engagement (z. B. Davis et al. 2022[12]; Boy et al. 2020[13]; Yang et al. 2022[14]). Ergänzende Kataloge liefern quantitative Orientierungen (MacKenzie 2019[15] zu Science‑Podcasts; Kuhle 2025[16] zu deutschen Hochschul‑Podcasts). Diese Arbeiten haben die Prioritäten für Transkription, Segmentierung und Relevanz‑Clustering beeinflusst.
Die oben genannten Arbeiten bilden zusammen die wissenschaftliche Basis: Nutzeranforderungen, methodische Konzepte (Wissensgraphen, FAIR‑Prinzipien), Evaluationsbefunde und Hinweise zur Qualitätskontrolle.
Aktueller Software‑Stand
Kurzgesagt: Seit 2021 existiert ein technischer Prototyp, der zeigt, wie ein gemeinsamer Index für wissenschaftliche Videos und Podcasts aussehen kann. Der Prototyp bündelt Metadaten, automatische Transkripte und einfache Werkzeuge für Annotation und Kuratierung. Die aktuelle Implementierung ist als Proof‑of‑Concept gedacht: funktional, aber noch nicht produktionsreif.
Technische Details: Die Architektur ist modular und serviceorientiert aufgebaut. Nachfolgend sind die einzelnen Komponenten zuerst knapp zusammengefasst und anschließend technisch beschrieben.
- Index / Datenmodell: Ein frei zugänglicher Index speichert für jedes Medium zentrale Angaben (Titel, Autor*in, Datum, Lizenz, Themen, Transkript‑Status) und ermöglicht damit Recherche und Verlinkung.
- Als zentrales Repository nutzen wir eine Wikibase‑Instanz als Linked‑Data‑Backend. Entitäten (Items) repräsentieren Medien, Episoden, Personen, Institutionen und Themen; Properties definieren Herkunft, Lizenzstatus, Transkript‑Metadaten, Segment‑Annotationen und Kuratierungsstatus. RDF/JSON‑LD‑Exports und ein SPARQL‑Endpoint erlauben interoperable Abfragen und Federation.[17]
- Metadaten‑Ingestion: Automatische Importer sammeln Basisinformationen aus gängigen Plattformen (YouTube, Podcast‑Hosts) und füllen den Index mit initialen Datensätzen.
- Connectoren extrahieren via APIs oder RSS/OPML Standardfelder (Titel, Beschreibung, Kanal, Datum, Dauer, Tags). Eine Transformationsschicht normalisiert Felder und erkennt Duplikate mit heuristischen Matching‑Regeln; validierte Datensätze werden programmgesteuert in Wikibase geschrieben.
- Transkription (ASR) und Nachbearbeitung: Automatische Spracherkennung liefert erste Transkripte, die Menschen nachkorrigieren können. So entstehen textuelle Repräsentationen, die Suche und Inhaltsanalyse ermöglichen.
- Die Pipeline ist pluggable: lokale Open‑Source‑Modelle (Whisper‑kompatibel) oder Cloud‑APIs können als Backends verwendet. Ergebnisse kommen mit Zeitstempeln und Confidence‑Werten in eine Nachbearbeitungs‑Queue; korrigierte Transkripte werden mit Lizenz‑ und Rechtsmetadaten im Index verknüpft.
- Annotation & Kuratierung: Nutzer*innen können Inhalte segmentieren, mit Themen und Quellen taggen und kurze Bewertungen abgeben; diese Arbeit bleibt menschlich‑geführt, unterstützt durch einfache Werkzeuge.
- Frontend‑Widgets (integriert in MediaWiki/Wikibase‑UI, ergänzt durch React‑Komponenten) erlauben Segmentmarkierung, Annotation von Zeitbereichen und Kommentar‑Threads. Rollen‑ und Aufgabenlisten (Quests) steuern Freiwilligenarbeit; Aktionen werden als Wikibase‑Statements versioniert.
- Verknüpfung zu Forschungsdaten (ORKG, Zenodo, etc.): Videos und Podcasts werden kontextualisiert, indem sie mit wissenschaftlichen Publikationen, DOIs und ORKG‑Einträgen verlinkt werden.
- Crosswalks zu ORKG‑IDs, DOIs und externen Repositorien sind implementiert; bei Importen werden Referenzen erkannt und als Properties in Wikibase gespeichert, damit Forschende Medien direkt in Forschungs‑Workflows einbinden können.[10]
- Deployment & Reproduzierbarkeit: Der Prototyp lässt sich lokal nachstarten, damit Partner Technologiebewertungen und Tests durchführen können.
- Die Services sind containerisiert (Docker Compose) und enthalten Start‑Skripte für Demo‑Daten. Für den Produktivbetrieb sind zusätzliche Hardening‑, Monitoring‑ und Backup‑Prozesse erforderlich.
- APIs & Exportformate: Daten können extern abgefragt und in offenen Formaten weiterverwendet werden.
- Geplante/teilweise implementierte Schnittstellen umfassen JSON/JSON‑LD Exporte, einen SPARQL‑Endpoint sowie REST‑Endpunkte für typische Abfragen (z. B. Episoden nach Thema). Exportformate orientieren sich an Linked‑Data‑Konventionen (RDF, JSON‑LD) für maximale Interoperabilität.[18]
- Entwicklungsstand heute und der Weg dorthin

Konzeptskizze (aktueller Stand)
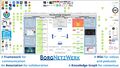
Erste Versuche, die gesamte Pipeline zu skizieren

Erste Entwicklungen mit Obsidian.md Interface
Erste Skizze der künftigen Oberfläche

Telinehmer-Übersicht zur Anforderungserhebung aus der MA Stehr

Ranking der wichtigsten Features laut Anforderungserhebung MA Stehr

Ranking der wichtigsten Filter-Kriterien laut Anforderungserhebung MA Stehr

Suchseite implementiert in MA Stehr

Detailseite implementiert in MA Stehr

Ergebnisse der Usability-Analyse in MA Stehr
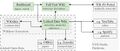
Übersicht zur Infrstruktur (aktueller Stand)

Übersicht zur Suche (aktueller Stand)

Übersicht zum Import (aktueller Stand)

Gesamt-Übersicht (aktueller Stand)



.png)





.drawio.jpg)
Datenerhebung
Finanz- und Projekt-Plan

In diesem Abschnitt fassen wir die einzelnen Funding-Goals aus dem Budget zusammen und ordnen sie in eine Meilenstein-Logik.
Ziel: klare Prioritäten, transparente Mittelverwendung und ein pragmatischer Fahrplan vom Prototyp zur Skalierung.
Die Reihenfolge orientiert sich an der Dringlichkeit: Rechtliche Klarheit und minimale Sichtbarkeit zuerst, Infrastruktur und Teamaufbau später.
Meilenstein 1: Kopf über Wasser
Ziel: Umgehend rechtliche Grundfragen klären, um handlungsfähig zu werden.
Rechtsgutachten (Mindestumfang): 5.000 €
Kompaktes Rechtsgutachten zur schnellen Klärung zentraler Rechtsfragen (erste Einschätzung, Risiken, Handlungsoptionen). Ermöglicht Entscheidungen zu Veröffentlichung, Einwilligungen und rechtlichen Mindestanforderungen.
Meilenstein 2: Treibholz

Ziel: Prototyp durch erste Nutzer:innen testen, Feedback sammeln und Kommunikations-/Outreach-Maßnahmen fahren, um Ehrenamtliche und Pilotpartner zu gewinnen.
Grafikdesign & Visuals: 5.000 €
Professionelle Grafiken für Web und Print (Teaser, Pitch-Deck, Social-Media-Visuals), um Sichtbarkeit zu gewinnen und Förderanträge / Partnerkommunikation professionell zu unterstützen.
Workshops (Basis): 1.000 €
Vier lokale Workshops zur Freiwilligengewinnung und Einweisung; Reise- und Materialkostenzuschuss, organisiert mit regionalen Partnern.
Podcast-Hosting (Minimal): 600 €
Jährliche Hostingkosten für Podcast-Materialien (Basis-Paket), um erste Inhalte zuverlässig zu publizieren.
Printmaterial: 1.000 €
Flyer und Handouts für Veranstaltungen und Outreach; gezielt zur Gewinnung von Ehrenamtlichen, Förderern und Kooperationspartnern.
Meilenstein 3: Floß
Ziel: Prototyp im Feld testen, Rechtssicherheit vertiefen und erste Community-Workflows etablieren.
Vollständiges Rechtsgutachten: 13.000 €
Umfassendes Rechtsgutachten zur Klärung von Urheber-, Datenschutz- und Plattformfragen mit konkreten Handlungsempfehlungen für den Echtbetrieb.
Design-Vergütung: 15.000 €
Angemessene Honorare für Designer*innen zur Erstellung von Markenassets, ausführlichen Kampagnen und professionellen Pitch-Materialien.
Workshops (Standard): 2.000 €
Vier Workshops mit moderatem Budget für Materialien und Honorare zur Schulung von Ehrenamtlichen und Stakeholder-Workshops zur Evaluation.
Podcast-Hosting (Erweitert): 2.000 €
Hosting inkl. Basisproduktion und kleiner Puffer für laufende Produktionskosten während des Piloten.
Meilenstein 4: Schiff
Ziel: Organisatorische und finanzielle Stabilität herstellen, regelmäßige Arbeit ermöglichen, erste Versicherungen und Räumlichkeiten absichern.
Juristische Begleitung (laufend): 12.000 €
Fortlaufende juristische Beratung während Aufbau und Pilotbetrieb, um Risiken frühzeitig zu adressieren und praktikable Betriebsregeln zu etablieren.
Workshops (groß): 6.000 €
Vier größere Workshops pro Jahr mit Catering und PR zur Reichweitensteigerung und Vernetzung.
Podcast-Produktion: 6.000 €
Budget für Produktion und Editing von Podcast-Inhalten sowie zur Professionalisierung der Ausspielungsqualität.
Vereinsrechtsschutz: 2.000 €
Rechtsschutzversicherung für Vereinsbelange zur Absicherung des Vorstands und der operativen Arbeit.
Coworking / Mietkosten: 2.000 €
Bedarfsmiete für Arbeitsräume und lokale Präsenz (z. B. Coworking-Space) zur Entlastung der Ehrenamtlichen und als Anlaufstelle für Treffen.
Haftpflichtversicherung: 4.000 €
Versicherung gegen Schäden Dritter bei Veranstaltungen und Vereinsaktivitäten.
Cyber-Versicherung: 2.000 €
Absicherung gegenüber Cyber-Risiken sowie Unterstützung bei Vorfallsreaktion.
D&O-Versicherung: 2.000 €
Schutz von Vorstandsmitgliedern gegen persönliche Haftungsrisiken aus Entscheidungen.
Meilenstein 5: Crew
Ziel: Technische Basis und Produktentwicklung ausbauen, damit das System größere Datenmengen und mehr Nutzer:innen zuverlässig bedienen kann.
Technische Infrastruktur: 120.000 €
Aufbau und laufende Pflege von Server-, Datenbank- und Analyseinfrastruktur inklusive Betrieb, Monitoring und Security-Maßnahmen.
Produktentwicklung (Features & UX): 180.000 €
Entwicklung neuer Funktionen, Nutzerforschung und Verbesserung der Benutzerfreundlichkeit zur Erhöhung der Nutzungsraten und Akzeptanz.
Internes Wissensmanagement: 20.000 €
Minijob für Recherche und Wissensaufbereitung bezüglich Vereins-Fragen und organisatorische Koordination.
Skalierung & Netzwerkaufbau: 180.000 €
Integration, Partnerschaften und Maßnahmen zur Reichweitensteigerung (z. B. Integrationen, APIs, Partner-Onboarding).
Content Moderation & Community-Management: 20.000 €
Minijob für Moderation, Freiwilligenkoordination und Community-Bindung.
Teilzeitstellen (Summe): 80.000 €
Aufstockung der Minijobs auf Teilzeitstellen.
Vollzeitstellen (Summe): 120.000 €
Aufstockung der Teilzeitstellen auf Vollzeitkräfte.
Förderplan
Community Funding
Für Spenden und Mitgliederbeiträge behalten wir flexible Mittel für kurzfristige Prioritäten (z. B. Zusatzworkshops, kurzfristige Rechtsprüfungen). Ebenso können hiermit Lücken geschlossen werden, wenn Funding für vorherige Teilschritte ausfallen sollte.
Mitgliederbeiträge
Spenden/Crowdfunding
Akademische Förderung
...
Vereins- und Stiftungs-Funding
NLnet
Wikimedia
https://de.wikipedia.org/wiki/Wikipedia:F%C3%B6rderung
Klaus Tschira Stiftung
Robert Bosch Stiftung
Hasso Plattner Foundation
Stiftung Wissenschaft und Demokratie
Mercator Stiftung
Hasso Plattner Foundation
Joachim Herz Stiftung
Verstetigung
BorgNetzWerk
TIB
Weitere
WMDE
Unterstützer
The Friends We Made Along the Way
Wir bedanken uns für deine Zeit und deine Spende. Selbst, wenn du uns nicht spenden könntest, können wir dir einen Blick auf diese Projekte und insbesondere diese Spenden-Aktionen empfehlen, die wir in den letzten 3 Jahren gefunden haben:
Name
Kurze Beschreibung der Bekanntschaft.
Kurze Beschreibung derer Spendenaktion.
Link.
- ↑ Übersetzt aus dem Englischen: Tim, the founder of the Netzwerk, was able to use automatic voice recognition to produce transcripts for audio interviews I have been doing over the last decade and more, leading to an invaluable resource for users of my podcast website. As someone who is very invested in freely accessible public outreach, I think this is just a hint at what is potentially possible. The more we can make information and analysis of information widely available, the fewer barriers there will be in education, communication, and so on, which can only be a good thing!
- ↑ https://de.wikipedia.org/wiki/Wikipedia:Wikisource
- ↑ https://www.wikidata.org/wiki/Wikidata:WikiProject_Limits_of_Wikidata
- ↑ Wittenborg, Tim; Tremel, Constantin Sebastian; Stehr, Niklas; Karras, Oliver; Stocker, Markus; Auer, Sören (2025). "SciCom Wiki: Fact-Checking and FAIR Knowledge Distribution for Scientific Videos and Podcasts". URL: https://doi.org/10.48550/arXiv.2505.07912.
- ↑ Rohde, Alida (2023). "Eine empirische Nutzerstudie des Open Research Knowledge Graphs als Werkzeug für die Wissenschaftskommunikation". Masterarbeit, Leibniz Universität Hannover. URL: https://doi.org/10.15488/15394.
- ↑ Wittenborg, Tim; Karras, Oliver; Auer, Sören (2024). "SWARM-SLR - Streamlined Workflow Automation for Machine-Actionable Systematic Literature Reviews". In: Linking Theory and Practice of Digital Libraries. Springer Nature Switzerland. DOI: 10.1007/978-3-031-72437-4_2.
- ↑ John, Lena Daniela (2024). "SciKGDash - Ein modulares Dashboard zur Kuratierung von Forschungswissensgraphen". Leibniz Universität Hannover. URL: https://doi.org/10.15488/17526.
- ↑ Tremel, Constantin Sebastian (2024). "Scientific Knowledge fit for society - Scoring scientific accuracy in climate change related news articles". Masterarbeit, Leibniz Universität Hannover. URL: https://doi.org/10.15488/17173.
- ↑ 10.0 10.1 Stehr, Niklas (2025). "Eine digitale Wissensinfrastruktur zur Bereitstellung von Informationen über wissenschaftliche Videos und Podcasts". Leibniz Universität Hannover. URL: https://doi.org/10.15488/18996.
- ↑ John, Lena; Ghanmi, Ahmed Malek; Wittenborg, Tim; Auer, Sören; Karras, Oliver (2026). "ExtracTable: Human-in-the-Loop Transformation of Scientific Corpora into Structured Knowledge". In: Linking Theory and Practice of Digital Libraries. Springer Nature Switzerland. URL: https://doi.org/10.1007/978-3-032-05409-8_27.
- ↑ Davis, Lloyd S. et al. (2022). "Infotainment May Increase Engagement with Science but It Can Decrease Perceptions of Seriousness". Sustainability.
- ↑ Boy, Bettina et al. (2020). "Audiovisual Science Communication on TV and YouTube". Frontiers in Communication.
- ↑ Yang, Shiyu et al. (2022). "The science of YouTube". PLOS ONE.
- ↑ MacKenzie, Lewis E. (2019). "Science podcasts: analysis of global production and output from 2004 to 2018". Royal Society Open Science.
- ↑ Kuhle, Birte et al. (2025). "Wi4impact: Influence of Science Blogs and Podcasts on Knowledge Transfer". GESIS.
- ↑ Rossenova, Lozana et al. (2022). "Wikidata and Wikibase as complementary research data management services for cultural heritage data".
- ↑ Wilkinson, Mark D. et al. (2016). "The FAIR Guiding Principles".